零基础自学用Python 3开发网络爬虫(四): 登录
今天的工作很有意思, 我们用 Python 来登录网站, 用Cookies记录登录信息, 然后就可以抓取登录之后才能看到的信息. 今天我们拿知乎网来做示范. 为什么是知乎? 这个很难解释, 但是肯定的是知乎这么大这么成功的网站完全不用我来帮他打广告. 知乎网的登录比较简单, 传输的时候没有对用户名和密码加密, 却又不失代表性, 有一个必须从主页跳转登录的过程.
不得不说一下, Fiddler 这个软件是 Tpircsboy 告诉我的. 感谢他给我带来这么好玩的东西.
第一步: 使用 Fiddler 观察浏览器行为
在开着 Fiddler 的条件下运行浏览器, 输入知乎网的网址 http://www.zhihu.com 回车后到 Fiddler 中就能看到捕捉到的连接信息. 在左边选中一条 200 连接, 在右边打开 Inspactors 透视图, 上方是该条连接的请求报文信息, 下方是响应报文信息.
其中 Raw 标签是显示报文的原文. 下方的响应报文很有可能是没有经过解压或者解码的, 这种情况他会在中间部位有一个小提示, 点击一下就能解码显示出原文了.
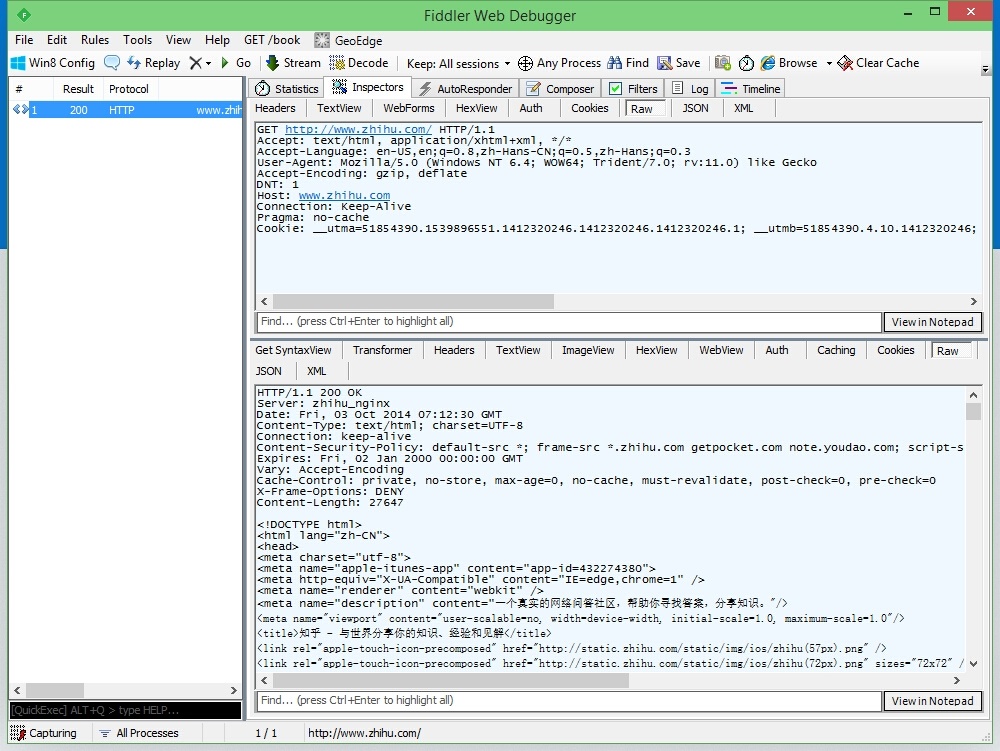
以上这个截图是在未登录的时候进入 http://www.zhihu.com 得到的. 现在我们来输入用户名和密码登陆知乎网, 再看看浏览器和知乎服务器之间发生了什么.

点击登陆后, 回到 Fiddler 里查看新出现的一个 200 链接. 我们浏览器携带者我的帐号密码给知乎服务器发送了一个 POST, 内容如下:
POST http://www.zhihu.com/login HTTP/1.1
Content-Type: application/x-www-form-urlencoded; charset=UTF-8
Accept: */*
X-Requested-With: XMLHttpRequest
Referer: http://www.zhihu.com/#signin
Accept-Language: en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3
Accept-Encoding: gzip, deflate
User-Agent: Mozilla/5.0 (Windows NT 6.4; WOW64; Trident/7.0; rv:11.0) like Gecko
Content-Length: 97
DNT: 1
Host: www.zhihu.com
Connection: Keep-Alive
Pragma: no-cache
Cookie: __utma=51854390.1539896551.1412320246.1412320246.1412320246.1; __utmb=51854390.6.10.1412320246; __utmc=51854390; __utmz=51854390.1412320246.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); __utmv=51854390.000–|3=entry_date=20141003=1_xsrf=4b41f6c7a9668187ccd8a610065b9718&email=此处涂黑%40gmail.com&password=此处不可见&rememberme=y
截图如下:

我的浏览器给 http://www.zhihu.com/login 这个网址(多了一个/login) 发送了一个POST, 内容都已经在上面列出来了, 有用户名, 有密码, 有一个”记住我”的 yes, 其中这个 WebForms 标签下 Fiddler 能够比较井井有条的列出来 POST 的内容. 所以我们用 Python 也发送相同的内容就能登录了. 但是这里出现了一个 Name 为 _xsrf 的项, 他的值是 4b41f6c7a9668187ccd8a610065b9718. 我们要先获取这个值, 然后才能给他发.
浏览器是如何获取的呢, 我们刚刚是先访问了 http://www.zhihu.com/ 这个网址, 就是首页, 然后登录的时候他却给 http://www.zhihu.com/login 这个网址发信息. 所以用侦探一般的思维去思考这个问题, 就会发现肯定是首页把 _xsrf 生成发送给我们, 然后我们再把这个 _xsrf 发送给 /login 这个 url. 这样一会儿过后我们就要从第一个 GET 得到的响应报文里面去寻找 _xsrf
截图下方的方框说明, 我们不仅登录成功了, 而且服务器还告诉我们的浏览器如何保存它给出的 Cookies 信息. 所以我们也要用 Python 把这些 Cookies 信息记录下来.
这样 Fiddler 的工作就基本结束了!
第二步: 解压缩
简单的写一个 GET 程序, 把知乎首页 GET 下来, 然后 decode() 一下解码, 结果报错. 仔细一看, 发现知乎网传给我们的是经过 gzip 压缩之后的数据. 这样我们就需要先对数据解压. Python 进行 gzip 解压很方便, 因为内置有库可以用. 代码片段如下:
import gzip
def ungzip(data):
try: # 尝试解压
print('正在解压.....')
data = gzip.decompress(data)
print('解压完毕!')
except:
print('未经压缩, 无需解压')
return data
通过 opener.read() 读取回来的数据, 经过 ungzip 自动处理后, 再来一遍 decode() 就可以得到解码后的 str 了
第二步: 使用正则表达式获取沙漠之舟
_xsrf 这个键的值在茫茫无际的互联网沙漠之中指引我们用正确的姿势来登录知乎, 所以 _xsrf 可谓沙漠之舟. 如果没有 _xsrf, 我们或许有用户名和密码也无法登录知乎(我没试过, 不过我们学校的教务系统确实如此) 如上文所说, 我们在第一遍 GET 的时候可以从响应报文中的 HTML 代码里面得到这个沙漠之舟. 如下函数实现了这个功能, 返回的 str 就是 _xsrf 的值.
import re
def getXSRF(data):
cer = re.compile('name="_xsrf" value="(.*)"', flags = 0)
strlist = cer.findall(data)
return strlist[0]
第三步: 发射 POST !!
集齐 _xsrf, id, password 三大法宝, 我们可以发射 POST 了. 这个 POST 一旦发射过去, 我们就登陆上了服务器, 服务器就会发给我们 Cookies. 本来处理 Cookies 是个麻烦的事情, 不过 Python 的 http.cookiejar 库给了我们很方便的解决方案, 只要在创建 opener 的时候将一个 HTTPCookieProcessor 放进去, Cookies 的事情就不用我们管了. 下面的代码体现了这一点.
import http.cookiejar
import urllib.request
def getOpener(head):
# deal with the Cookies
cj = http.cookiejar.CookieJar()
pro = urllib.request.HTTPCookieProcessor(cj)
opener = urllib.request.build_opener(pro)
header = []
for key, value in head.items():
elem = (key, value)
header.append(elem)
opener.addheaders = header
return opener
getOpener 函数接收一个 head 参数, 这个参数是一个字典. 函数把字典转换成元组集合, 放进 opener. 这样我们建立的这个 opener 就有两大功能:
- 自动处理使用 opener 过程中遇到的 Cookies
- 自动在发出的 GET 或者 POST 请求中加上自定义的 Header
第四部: 正式运行
正式运行还差一点点, 我们要把要 POST 的数据弄成 opener.open() 支持的格式. 所以还要 urllib.parse 库里的 urlencode() 函数. 这个函数可以把 字典 或者 元组集合 类型的数据转换成 & 连接的 str.
str 还不行, 还要通过 encode() 来编码, 才能当作 opener.open() 或者 urlopen() 的 POST 数据参数来使用. 代码如下:
url = 'http://www.zhihu.com/'
opener = getOpener(header)
op = opener.open(url)
data = op.read()
data = ungzip(data) # 解压
_xsrf = getXSRF(data.decode())
url += 'login'
id = '这里填你的知乎帐号'
password = '这里填你的知乎密码'
postDict = {
'_xsrf':_xsrf,
'email': id,
'password': password,
'rememberme': 'y'
}
postData = urllib.parse.urlencode(postDict).encode()
op = opener.open(url, postData)
data = op.read()
data = ungzip(data)
print(data.decode()) # 你可以根据你的喜欢来处理抓取回来的数据了!
代码运行后, 我们发现自己关注的人的动态(显示在登陆后的知乎首页的那些), 都被抓取回来了. 下一步做一个统计分析器, 或者自动推送器, 或者内容分级自动分类器, 都可以.
完整代码如下:
import gzip
import re
import http.cookiejar
import urllib.request
import urllib.parse
def ungzip(data):
try: # 尝试解压
print('正在解压.....')
data = gzip.decompress(data)
print('解压完毕!')
except:
print('未经压缩, 无需解压')
return data
def getXSRF(data):
cer = re.compile('name="_xsrf" value="(.*)"', flags = 0)
strlist = cer.findall(data)
return strlist[0]
def getOpener(head):
# deal with the Cookies
cj = http.cookiejar.CookieJar()
pro = urllib.request.HTTPCookieProcessor(cj)
opener = urllib.request.build_opener(pro)
header = []
for key, value in head.items():
elem = (key, value)
header.append(elem)
opener.addheaders = header
return opener
header = {
'Connection': 'Keep-Alive',
'Accept': 'text/html, application/xhtml+xml, */*',
'Accept-Language': 'en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko',
'Accept-Encoding': 'gzip, deflate',
'Host': 'www.zhihu.com',
'DNT': '1'
}
url = 'http://www.zhihu.com/'
opener = getOpener(header)
op = opener.open(url)
data = op.read()
data = ungzip(data) # 解压
_xsrf = getXSRF(data.decode())
url += 'login'
id = '这里填你的知乎帐号'
password = '这里填你的知乎密码'
postDict = {
'_xsrf':_xsrf,
'email': id,
'password': password,
'rememberme': 'y'
}
postData = urllib.parse.urlencode(postDict).encode()
op = opener.open(url, postData)
data = op.read()
data = ungzip(data)
print(data.decode())
全扫一遍,谢谢
代码展示插件不错
真心不错 标准库里好多都没看过,惭愧直接从消息报头的 Set-Cookie 里得到的 _xsrf 对于这个够了
前面的fiddler其实是抓包用的,类似这种前端登录动作,楼主应该用casperjs
谢推荐
http://docs.python-requests.org/en/latest/
谢推荐
请教一下python把coockie文件放在哪了,还是一直在内存里存着
非常谢谢让我知道有Fiddler 这个软件,真心好用
内存里
楼主快点更新~~
请问一下,楼主是如何知道知乎返回的数据是经过加密的呢?
最近打比赛没更新,返回的数据是压缩的,从header可看到,不是加密的
恩是的这一点我看到了~没有经过思考就提问。我错了~~
还有_xsrf=4b41f6c7a9668187ccd8a610065b9718这个_xsrf其实是可以不submit的。它已经作为cookie写进去了。楼主可以再仔细看看登入www.zhihu.com的返回的header
看到这个,我太惭愧了~~泪奔去~
噢!
我觉得这个是用来防止跨站请求伪造 http://baike.baidu.com/view/1609487.htm?fr=aladdin
精悍,不过知乎目前已经修复了,采用动态验证码来作为登录验证,期待破解带有动态验证码的。。。。
niubi
非常感谢,条理性很强,很有帮助!
如果有验证码怎么办?
收获挺多
你好,直接执行你的代码返回的是“urllib.error.HTTPError: HTTP Error 405: Method Not Allowed”,什么原因呢?
同问
要验证码啦,post里面还需要captcha的参数
手动输入
captcha的参数貌似被urllib.parse.urlencode处理以后就读不出来,还是op = opener.open(url, postData)每次使用都会产生一个新的验证码?所以r = requests.session().get(‘http://www.zhihu.com/captcha.gif?r’+str(int(time.time()*1000)))with open(‘code.gif’, ‘wb’) as f:f.write(r.content)读到的验证码总是不对的?
因为post出去的captcha时候,并不能识别session就是你get验证码的url时候的session新手不知道怎么用urllib处理这个问题。我就改用requests的post出captcha,如下res = _session.post(url, data=postDict)json = res.json()print(json)显示登入成功
requests的话如何分析数据呢?或者说如何获取数据呢?
question_url = ‘http://www.zhihu.com/question/26541545‘ res = _session.get(question_url, ) print(res.text) 我也还在学习中,分析数据还不会 TAT,获取数据如上,后面就是如何提取里面的url和内容就不太清楚,估计正则表达式要比较熟练吧
我在执行你的代码的时候出错,好像没别人遇到,貌似解压后,数据类型丢了_xsrf = getXSRF(data.decode()),AttributeError: ‘NoneType’ object has no attribute ‘decode’
good
学习了,我最近也在学爬虫…不过因为实验室的原因一开始就在用Scrapy框架,是应该向你这样先把整个流程过一遍的.
不行有验证码。还是js的
现在的知乎要验证码了好悲伤0.0
爬不动了,要验证码,我哭死了
手动输入验证码:url_captcha_prefix = url_zhihu + ‘/captcha.gif?r=’url_captcha = url_captcha_prefix + str(int(time.time() * 1000))# 获取验证码cap_content = urllib.request.urlopen(url_captcha).read()with open(‘captcha.gif’, ‘wb’) as cap_file: cap_file.write(cap_content)im = PIL.Image.open(‘captcha.gif’)im.show()captcha = input(‘capture:’)…dict_post = { ‘_xsrf’: xsrf, ’email’: id, ‘password’: password, ‘captcha’: captcha, ‘remember_me’: ‘False’}
正好最近也在学习,基于上面的代码,放一个需要验证码的手机登录版本,在Pycharm上跑登录成功,仅供参考import gzipimport reimport http.cookiejarimport urllib.requestimport urllib.parsefrom PIL import Imageimport timeimport jsondef ungzip(data): try: # 尝试解压 print(‘正在解压…..’) data = gzip.decompress(data) print(‘解压完毕!’) except: pass return datadef getXSRF(data): cer = re.compile(‘name=”_xsrf” value=”(.*)”‘, flags = 0) strlist = cer.findall(data) return strlist[0]def getOpener(head): # deal with the Cookies cj = http.cookiejar.CookieJar() pro = urllib.request.HTTPCookieProcessor(cj) opener = urllib.request.build_opener(pro) header = [] for key, value in head.items(): elem = (key, value) header.append(elem) opener.addheaders = header return openerheader = { ‘Connection’: ‘Keep-Alive’, ‘Accept’: ‘text/html, application/xhtml+xml, */*’, ‘Accept-Language’: ‘en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3’, ‘User-Agent’: ‘Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko’, ‘Accept-Encoding’: ‘gzip, deflate’, ‘Host’: ‘www.zhihu.com’, ‘DNT’: ‘1’}url = ‘http://www.zhihu.com/‘opener = getOpener(header)op = opener.open(url)data = op.read()data = ungzip(data) _xsrf = getXSRF(data.decode())# 获取验证码t = str(int(time.time() * 1000))url_captcha = ‘http://www.zhihu.com/captcha.gif?r=‘ + t cap_content = opener.open(url_captcha).read()with open(‘captcha.gif’, ‘wb’) as cap_file: cap_file.write(cap_content)im = Image.open(‘captcha.gif’)im.show()captcha = input(‘请输入验证码:’)url += ‘login/phone_num’id = input(‘输入手机号登陆:’)password = input(‘输入密码:’)postDict = { ‘_xsrf’: _xsrf, ‘phone_num’: id, ‘password’: password, ‘remember_me’: ‘true’}try: postData = urllib.parse.urlencode(postDict).encode() op = opener.open(url, postData) data = op.read() data = json.loads(ungzip(data).decode()) print(data[‘msg’])except: postDict[‘captcha’] = captcha postData = urllib.parse.urlencode(postDict).encode() op = opener.open(url, postData) data = op.read() data = json.loads(ungzip(data).decode()) print(data[‘msg’])
请问登录成功之后,应该如何GET数据?
知乎已在2015年年末启用https了。。。
Traceback (most recent call last): File “C:/Users/Administrator/PycharmProjects/package_text/another_first.py”, line 41, in opener = getopener(header) File “C:/Users/Administrator/PycharmProjects/package_text/another_first.py”, line 26, in getopener opener.addheaders(elem)TypeError: ‘list’ object is not callable这个问题怎么解决
opener.addheaders(elem) 应该是opener.addheaders = header但是又有问题了Traceback (most recent call last): File “C:/Users/Administrator/PycharmProjects/package_text/new.py”, line 45, in _xsrf = getXSRF(data.decode()) File “C:/Users/Administrator/PycharmProjects/package_text/new.py”, line 15, in getXSRF return strlist[0]IndexError: list index out of range